
翻译自:Rand Fishkin 文章: https://sparktoro.com/blog/how-can-my-brand-appear-in-answers-from-chatgpt-perplexity-gemini-and-other-ai-llm-tools/
营销人员、创始人和企业主开始询问他们的品牌如何才能在 ChatGPT、Perplexity 和 Gemini 等 AI/LLM 工具给出的答案中回归,这并不奇怪。但令人震惊的是,找到有关如何做到这一点的高质量、准确的信息是多么困难。
当然,你可以直接问 ChatGPT(第一个答案还不错,第二个问题的建议 2-10 也不错;建议 1 是……有问题的,视频中有更多相关内容)。然而,要弄清问题的核心,需要充分了解 LLM 给出的答案是如何以及为什么会这样。有了这些知识,我们就可以明智地选择在哪里投资我们的社交媒体、内容营销、公关和媒体投资、合作伙伴关系以及对网络的贡献。
在本周的 5 分钟白板中(抱歉,总共只有 9 分钟,因为该主题需要更彻底的演练),我将解释:
- LLM 如何确定在回答中哪些词应该放在其他词后面
- 营销人员、创始人和创作者可以做些什么来影响这些结果
- 了解可能用于法学硕士训练数据的来源的方法
- 寻找影响训练数据的机会的策略
当用户提出相关问题时,如何让你的品牌、你的公司、你的名字成为大型语言模型给出的答案?
这基本上就是过去 Google、Bing、Dogpile、Lycos 和 HotBot 的 SEO(搜索引擎优化),只不过这些新模型(AI)的做法完全不同。Google 搜索的货币是链接。您在这些结果中的排名方式是通过链接、相关内容、智能关键字使用以及搜索引擎抓取的来源对您作品的引用。
在大型语言模型中排名的方式并非如此。大型语言模型的货币不是链接。大型语言模型的货币是训练数据中的提及(具体而言,频繁出现在其他单词附近的单词)。让我告诉你我的意思。

这些结果让我很尴尬。我觉得它们并不好。因此,这个视频中,谷歌的 AI 概述答案也不是很好。尽管他们确实引用了Seer Interactive ,其中有一些相当不错的东西,我在评论中链接到了他们。
好吧。首先,我喜欢 Stephen Wolfram 去年写的关于ChatGPT 工作原理的文章。我认为这是对大型语言模型如何决定给出什么答案的最清晰、最容易理解的答案。在他关于这个问题的文章“ChatGPT 在做什么,为什么它有效?”中,他展示了这张特别的图表,我认为这很有帮助。

人工智能最棒的地方在于它能够学习、预测、制造、理解,然后还有一个百分比。
他解释说,这个百分比来自训练数据。本质上,如果 ChatGPT 发现,当“人工智能最棒的地方在于它能够……”这句话出现在网络上时,“学习”一词出现的频率远高于“预测”,那么他们就更有可能显示“学习”而不是“预测”。
这就是你获得大型语言模型输出的方式,有些人将其描述为“辛辣的自动完成”或“频繁出现在其他单词后面的单词”。在我看来,这是一种非常好的思考人工智能工具的方式。所以我问 ChatGPT,西雅图最好的高级餐厅有哪些?而且,你可以看到我会为你隐藏这个。

您可以看到Canlis是最佳结果。我实际上多次向 ChatGPT 询问了同样的问题。每次我都会得到不同的结果,这是大型语言模型的挫败之处之一,因为正如 Wolfram 在此处的示例中所示,根据训练模型或训练数据,您看到任何单词出现在任何其他单词之后的概率是百分比。因此,Canlis 几乎总是(但不是每次)出现在第一个结果中。
当我运行这个程序五次、十次时,我想我看到了七次或类似的结果。而其他的,Herbfarm 经常出现在他们的流动站中,这已经很多年没有出现了。而且不幸的是,他们提到了一年前去世的厨师 Thierry Rautureau 。但其他大多数答案都是合理的,它们与 Google 在此处提供的答案相差不大。
您可以看到,当我搜索西雅图的高级餐厅时,Canlis 是第一个结果。Altura 是第二个。
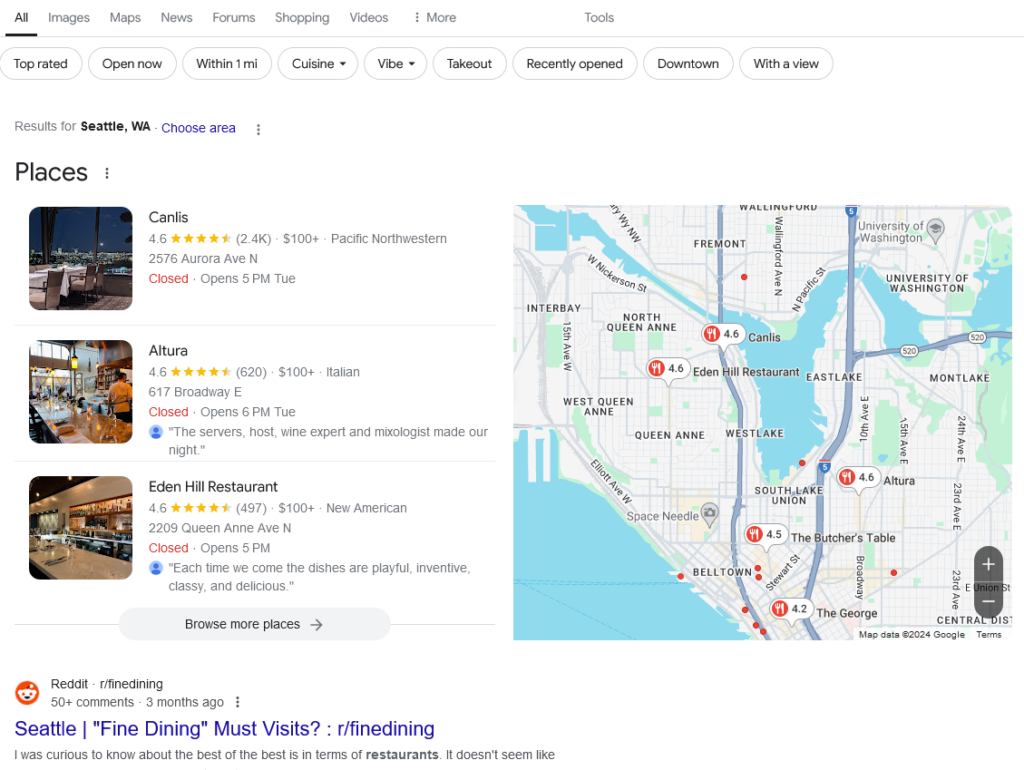
如果您试图进入这些结果,我会这样做。例如,如果您是 Eden Hill 餐厅或西雅图其他高级餐厅之一,并且您没有在 ChatGPT 或其他大型语言模型答案中看到自己的名字,并且您认为您的品牌或公司出现在这些 LLM 结果中很重要,那么下一步该怎么做?
以下是我要做的事情:
我会在网上查找所有提到美食、餐馆和西雅图的地方。您可以看到,我特意用引号括起来,而不是试图将其作为标准查询,这是出于某种原因。这样我在这里看到的结果就使用了这种语言,因为,当然,我们正在寻找经常出现在其他单词后面的单词,所以我们想在网上找到这些地方。
然后,我们希望确保我们的品牌在这里被提及。现在,让您的餐厅在EATER 上被列入西雅图最适合特殊场合的餐厅名单是否非常困难?是的。确实如此。这很难。这将是一个公关过程和宣传过程,但这值得吗?
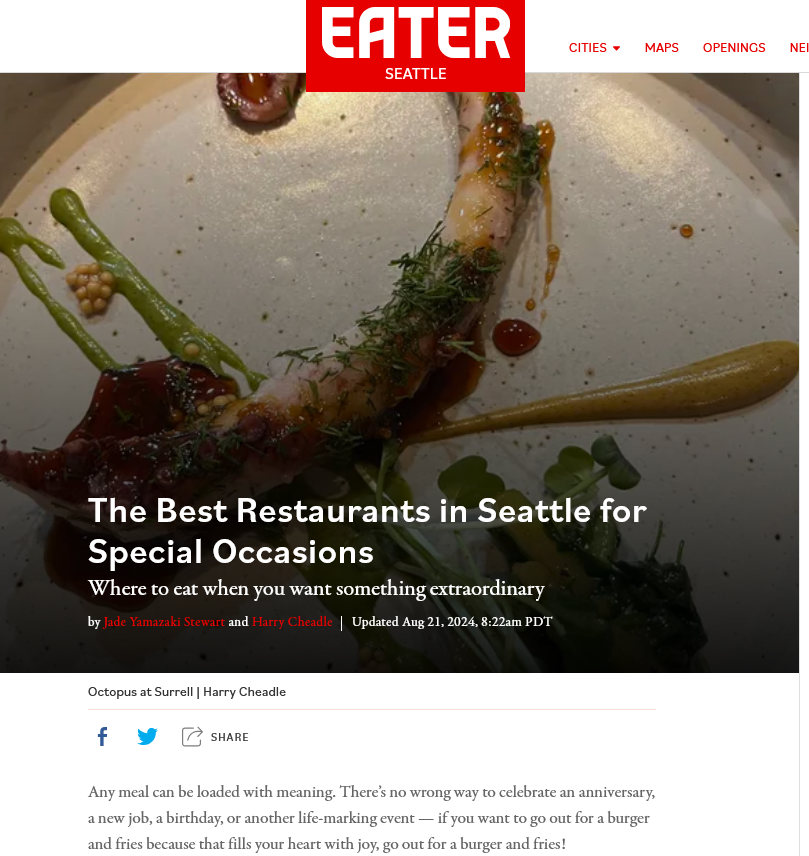
绝对如此。这不仅对大型语言模型有价值,尽管它肯定对它们有用,而且其他人可能会点击此结果并通过它找到你。你在这里找到的几乎所有结果都是如此。所以这是一个手动过程。
这是解决此问题的一种方式。另一种方式相当有趣,我发现大型语言模型本身非常清楚哪些网站可能对大型语言模型训练数据有所贡献。因此,您可以询问 ChatGPT 或您选择的 LLM,Conde Nast Traveler(CN Traveler 网站)用于 LLM 训练数据的可能性有多大。正如您在此处看到的,从规模上看,这就是我向 ChatGPT 询问的问题。

以零(完全不可能)到一百(几乎肯定)的等级来衡量,以下网站被用于 Gemini 和 ChatGPT 等大型语言模型的训练数据的可能性和困惑度有多大。
然后我给它一个网站列表,它会给我一些估计值。我认为这些并不完美。如果你问它十次,它会给你十个不同的答案。但它几乎总是会说一些真实的事情,比如 Reddit 很可能在这里被使用。我们知道他们正在将数据出售给大型语言模型,因此它是训练数据的常见来源。Eater 和 CN traveler,以及纽约时报,排名相当高。然后是较小的网站、更小众的网站、更难抓取的地方,你可以看到其中的不同数字。
例如,出于隐私原因,用户生成的内容有时会被排除在外。这些都是真实的,并且已经写过关于大型语言模型流程的文章,这真的很有用。现在让我给你展示一些非常巧妙的东西。
您可以进入 SparkToro,然后问自己,嘿,对于搜索关键词西雅图高级餐饮的人来说,他们可能会访问哪些网站?哪些网站与这些受众群体的亲和力较高?您可以在这里看到,其中一些网站包括四季酒店,这是西雅图一家非常豪华的酒店,人们可能会在这里找到可能寻找高级餐饮的旅行者。您可以在这里看到阿拉斯加航空,西雅图是阿拉斯加航空的枢纽和中心。

因此,许多来这座城市的游客都会从那里进入,这并不奇怪。因此,这与大型语言模型在训练中可能使用的内容不同。但是,您可以获取此列表,导出 CSV。您可以打开该 CSV,然后复制这些域,然后您就可以执行我刚刚使用 ChatGPT 展示的操作。
针对此列表再做一次。

繁荣。
现在我们可能会得到关于这些事情的估计。再说一次,我不会完全按照字面意思来理解这些结果,但我会用它们来表明你可能需要做公关和评论营销,以及推销:
- “嘿,我们可以和你一起写一篇文章吗?”
- “我们可以进入你的下一期吗?”
- “下次您谈论餐厅时,我们希望能够考虑到我们的餐厅。”
- “我们可以邀请你的评论家来这里吗?”
无论你做什么事。
而且不仅仅是SparkToro。我推荐您使用另一种工具。这就是BuzzSumo。他们有一个我喜欢的警报功能,我已经使用了很多年。所以我在这里所做的就是创建,让我把它放大,这样你就能看到它了。
因此,您可以为关键字创建警报。我将这个搜索命名为 Fine Dining Seattle,我想监控哪个关键字?我想监控 Fine Dining,匹配精确匹配,并且它必须完全包含关键字 Seattle,我希望那里有摘要。BuzzSumo 会做的一件好事是,它会给我预览它看到的结果。那么,人们在网上发布包含 Fine Dining 和 Seattle 字样的内容的地方在哪里呢?然后您可以看到这些地方,比如 Elite Sports Tours 和 Washington Tasting Room dot com 以及 Eater,这些都是我们知道的。
这个过程本质上是进行外展、公关和内容营销,并确保你的词语出现在网络上其他词语之后,出现在 LLM 可能获取其训练数据的地方,这就是将你的品牌融入大型语言模型答案的方法。
如果您像坎利斯一样,能够成为西雅图高级餐饮的代名词,那么当大型语言模型为您提供结果时,您将会频繁出现在结果的顶部。